Project Overview
This project demonstrates how large-scale crime datasets can be efficiently processed and analyzed using cloud-based big data technologies. The system ingests millions of police-recorded crime records and applies distributed analytics to identify trends, geographic hotspots, and relationships between different crime types.
Many organizations in insurance, public safety, and urban planning struggle with national-scale datasets due to storage, processing, and performance limitations. This solution bridges that gap using scalable cloud infrastructure.
Project Results & Visual Output
Below are sample visualizations and outputs from our distributed analytics pipeline, demonstrating trends, spatial crime patterns, and correlations between crime types.
Crime Analytics Overview
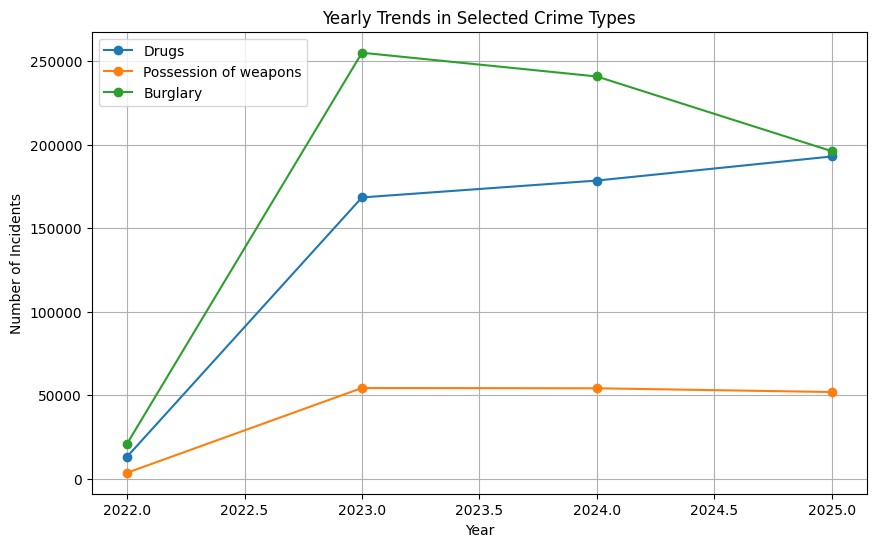
Crime Analytics Trends
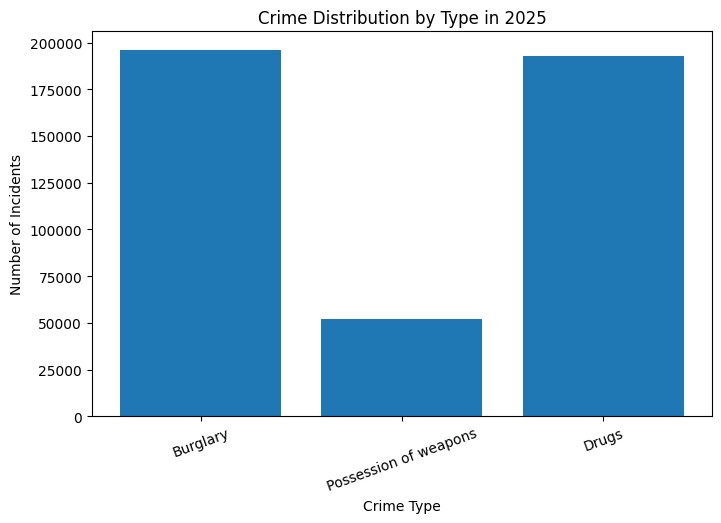
Project Goal
To design a scalable, cost-efficient cloud analytics solution capable of processing tens of millions of records while delivering interpretable, actionable insights for data-driven decision-making.
Key Features & Achievements
- Built an end-to-end analytics pipeline using Azure IaaS and Apache Spark
- Processed over 18 million crime records using distributed computing
- Analyzed long-term crime trends across multiple years
- Identified spatial crime concentration at neighbourhood (LSOA) level
- Quantified relationships between drug offenses and weapons-related crime
- Balanced scalability, transparency, and computational efficiency
Technologies Used
Big Data & Cloud
- Apache Spark (PySpark)
- Azure Virtual Machines
Storage
- Azure Blob Storage (Data Lake Architecture)
Analytics
- Distributed Aggregation
- Statistical Analysis
Visualization & Environment
- Matplotlib, Pandas
- Jupyter Notebook, Linux
Use Cases
- Insurance risk assessment and underwriting
- Urban safety and crime hotspot analysis
- Public policy and resource allocation
- Smart city planning and analytics
- Large-scale data exploration and reporting
What This Project Demonstrates
This project delivers a production-style big data analytics solution that scales to national datasets, integrates cloud infrastructure with distributed processing, and produces actionable insights while remaining cost-efficient and reproducible.